p4_HydroNet-Multi-scale
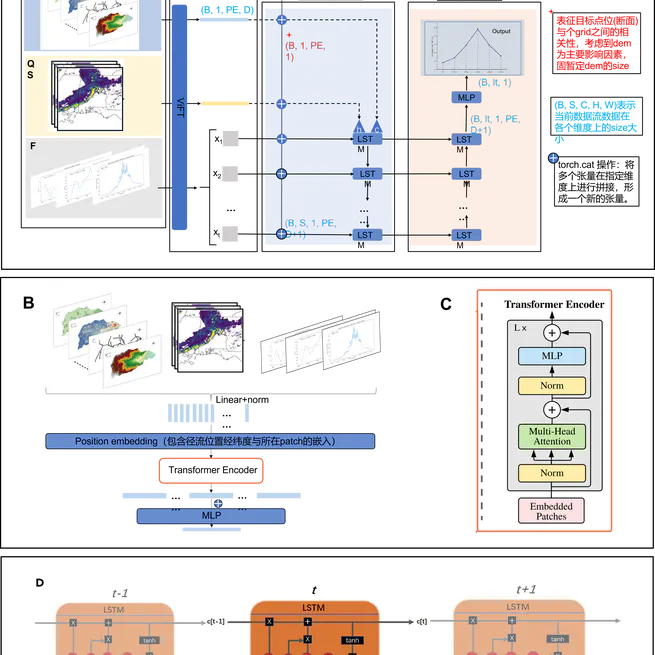
This project aims to build model mainly uses the vision fusion transformer (ViFT) structure based on transformer to extract the spatial information of meteorological ground elements under different spatial resolutions, and adds text, mainly the longitude and latitude information of target sites or sections, as a cue word.
May 26, 2024